RL
In RL, algorithms, referred to as agents, learn to make decisions by interacting with an environment. The agent selects an action to take based on its current state and then receives a reward or penalty based on the outcome of that action. The goal is to learn a policy—a mapping from states to actions—that maximizes the cumulative reward over time.
This type of ML is quite distinct from SL as it does not rely on labeled input/output pairs and does not require explicit correction of suboptimal actions. Instead, it focuses on finding a balance between exploration (trying new actions) and exploitation (using known information to maximize the reward).
RL has been successfully applied in various domains, including the following:
- Game playing: AI agents are trained to play and excel at complex games, such as Go, chess, and various video games, often surpassing human expert performance
- Robotics: Robots learn to perform tasks such as walking, picking up objects, or navigating through challenging terrain through trial and error
- Autonomous vehicles: RL is used to develop systems that can make real-time driving decisions in dynamic and unpredictable environments
OpenAI’s pioneering work in using RL with human feedback (RLHF) has been instrumental in developing AI models such as ChatGPT. By incorporating human preferences, these models are trained to generate responses that are not only relevant but also aligned with human values, enhancing their helpfulness and minimizing potential harm.
A typical flow for an RL problem would look something like this:
- The agent receives state S from the environment.
- The agent takes action A based on policy π.
- The environment presents a new state S and reward R to the agent.
- The reward informs the agent of the action’s effectiveness.
- The agent updates policy π to increase future rewards.
Overview of the types of ML
Of the three types of ML – SL, UL, and RL – we can imagine the world of ML as something like the depiction in Figure 10.7:
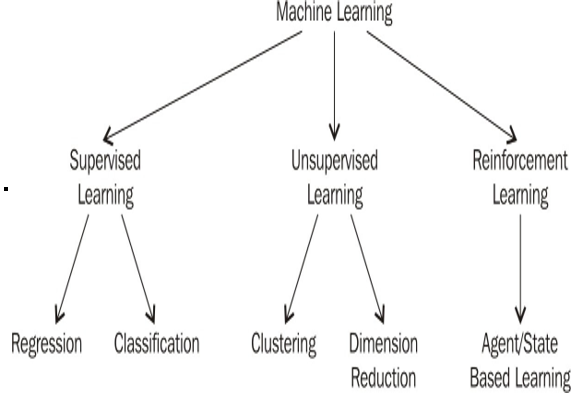
Figure 10.7 – Our family tree of ML has three main branches: SL, UL, and RL