UL
The second type of ML on our list does not deal with making predictions but has a much more open objective. UL takes in a set of predictors and utilizes relationships between the predictors in order to accomplish tasks such as the following:
- It reduces the dimension of the data by condensing variables together. An example of this would be file compression. Compression works by utilizing patterns in the data and representing the data in a smaller format. This is referred to as dimension reduction.
- It finds groups of observations that behave similarly and groups them together. This is called clustering.
Both of these are examples of UL because they do not attempt to find a relationship between predictors and a specific response and therefore are not used to make predictions of any kind. Unsupervised models, instead, are utilized to find organizations and representations of the data that were previously unknown.
Figure 10.5 gives a representation of a cluster analysis:
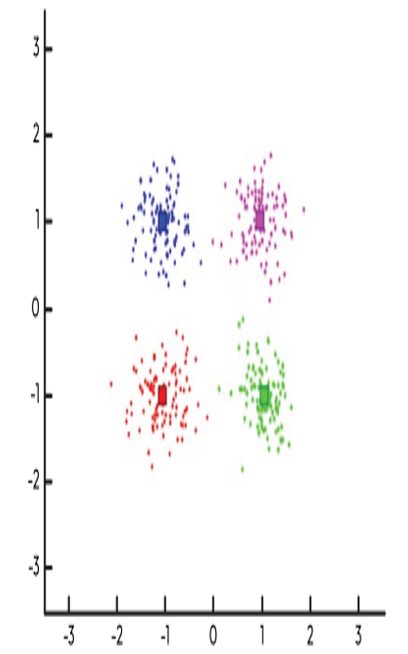
Figure 10.5 – Cluster analysis groups together similar data points to add a layer of interpretation on top of raw data
The model will recognize that each uniquely colored cluster of observations is similar to another but different from the other clusters.
A big advantage of UL is that it does not require labeled data, which means that it is much easier to get data that complies with UL models. Of course, a drawback to this is that we lose all predictive power because the response variable holds the information to make predictions and, without it, our model will be hopeless in making any sort of predictions.
A big drawback is that it is difficult to see how well we are doing. In a regression or classification problem, we can easily tell how well our models are predicting by comparing our models’ answers to the actual answers. For example, if our supervised model predicts rain and it is sunny outside, the prediction is incorrect. If our supervised model predicts the price will go up by 1 dollar and it goes up by 99 cents, our prediction is very close! In unsupervised modeling, this concept is foreign because we have no answer to compare our models to. Unsupervised models merely suggest differences and similarities that then require a human’s interpretation, as visualized in Figure 10.6:
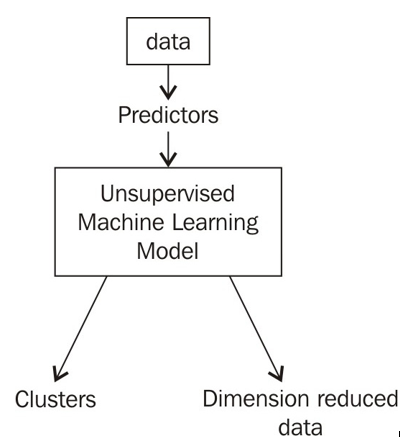
Figure 10.6 – Unsupervised models don’t have a notion of a “target” and instead focus on adding a layer of structure on top of raw data
In short, the main goal of unsupervised models is to find similarities and differences between data observations and use these comparisons to add structure on top of otherwise raw and unstructured data.
Moving in a very different direction is our final type of ML. To be honest with you, we don’t have the time nor the pages in this book to cover our next topic with the respect it deserves, but it merits a place in our text regardless.